Tutorial: End-to-end Kubeflow on GCP
Out of date
This guide contains outdated information pertaining to Kubeflow 1.0. This guide needs to be updated for Kubeflow 1.1.This guide walks you through an end-to-end example of Kubeflow on Google Cloud Platform (GCP) using a Jupyter notebook, mnist_gcp.ipynb. By working through the notebook, you learn how to deploy Kubeflow on Kubernetes Engine (GKE), train an MNIST machine learning model for image classification, and use the model for online inference (also known as online prediction).
Introductions
Overview of GCP and GKE
Google Cloud Platform (GCP) is a suite of cloud computing services running on Google infrastructure. The services include compute power, data storage, data analytics, and machine learning.
The Cloud SDK is a set of tools that you can use to interact with
GCP from the command line, including the gcloud command and others.
Kubernetes Engine (GKE) is a managed service on GCP where you can deploy containerized applications. You describe the resources that your application needs, and GKE provisions and manages the underlying cloud resources.
Here’s a list of the primary GCP services that you use when following this guide:
The model and the data
This tutorial trains a TensorFlow model on the MNIST dataset, which is the hello world for machine learning.
The MNIST dataset contains a large number of images of hand-written digits in the range 0 to 9, as well as the labels identifying the digit in each image.
After training, the model can classify incoming images into 10 categories
(0 to 9) based on what it’s learned about handwritten images. In other words,
you send an image to the model, and the model does its best to identify the
digit shown in the image.
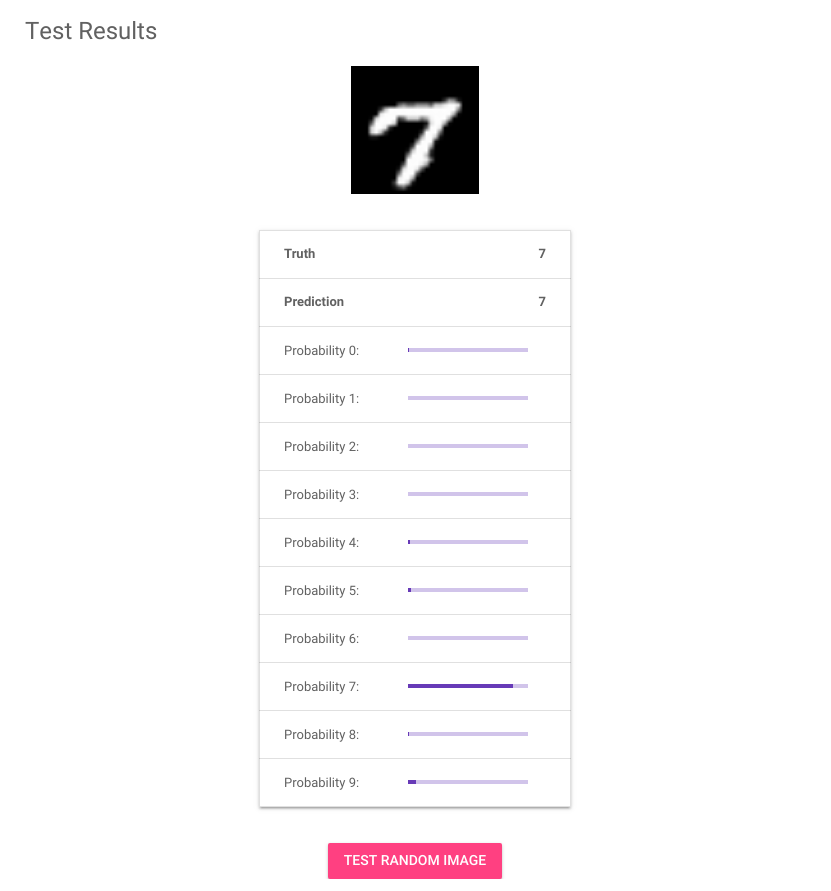
In the above screenshot, the image shows a hand-written 7. This image was the input to the model. The table below the image shows a bar graph for each classification label from 0 to 9, as output by the model. Each bar represents the probability that the image matches the respective label. Judging by this screenshot, the model seems pretty confident that this image is a 7.
The overall workflow
The following diagram shows what you accomplish by following this guide:

In summary:
-
Training the model:
- Packaging a TensorFlow program in a Kubernetes container.
- Uploading the container to Container Registry.
- Submitting a TensorFlow training (tf.train) job.
-
Using the model for prediction (inference):
- Saving the trained model to Cloud Storage.
- Using TensorFlow Serving to serve the model.
- Running a simple web app to send a prediction request to the model and display the result.
It’s time to get started!
Set up and run the MNIST tutorial on GCP
-
Follow the GCP instructions to deploy Kubeflow with Cloud Identity-Aware Proxy (IAP).
-
Launch a Jupyter notebook in your Kubeflow cluster. See the guide to setting up your notebooks. Note: This tutorial has been tested with the Tensorflow 1.15 CPU image as the baseline image for the notebook.
-
Launch a terminal in Jupyter and clone the Kubeflow examples repository:
git clone https://github.com/kubeflow/examples.git git_kubeflow-examples-
Tip: When you start a terminal in Jupyter, run the command
bashto start a bash terminal which is much more friendly than the default shell. -
Tip: You can change the URL for your notebook from ‘/tree’ to ‘/lab’ to switch to using JupyterLab.
-
-
Open the notebook
mnist/mnist_gcp.ipynb. -
Follow the instructions in the notebook to train and deploy MNIST on Kubeflow.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.